Projetos
![]()
1. Extração e Análise de Dados dos Docentes da Unesa da Plataforma Lattes
Integrantes
| Nome | Função |
|---|---|
| André Eppinghaus | Coordenador |
| George Mendes Silva de Oliveira | Desenvolvedor |
| Maria Vitória Quirino Batista | Desenvolvedora |
| Matheus da Silva Ferreira | Desenvolvedor |
| Alexia de Souza Martins | Desenvolvedora |
DIAGNÓSTICO E TEORIZAÇÃO
Identificação das partes interessadas e parceiros
O projeto do LTD realizado no período 2032.2 foi desenvolvido para atender a Coordenadora Nacional de Pesquisa, Extensão e Internacionalização, localizada na Diretoria de Ensino Av. das Américas 4200, Bloco 5 - 2º andar. Centro Empresarial Barra Shopping – Barra da Tijuca Rio de Janeiro – RJ - CEP 22.640-102 com a parte interessada a Dra. Larissa Clare Pochmann da Silva.
Problemática e/ou problemas identificados
No projeto anterior, o Setor Nacional de Pesquisa, Extensão e internacionalização da Universidade possui uma equipe reduzida e necessita analisar a produtividade de todos os docentes para a produção dos índices de produtividade: IPPGR3 e IPEI. Porém, mesmo a instituição mantendo um contrato com uma empresa para a extração dos dados dos docentes a partir da Plataforma Lattes do CNPq, os dados são gerados em planilhas. Além disso, as planilhas são apresentadas em um formato não-estruturado (Figura 1).
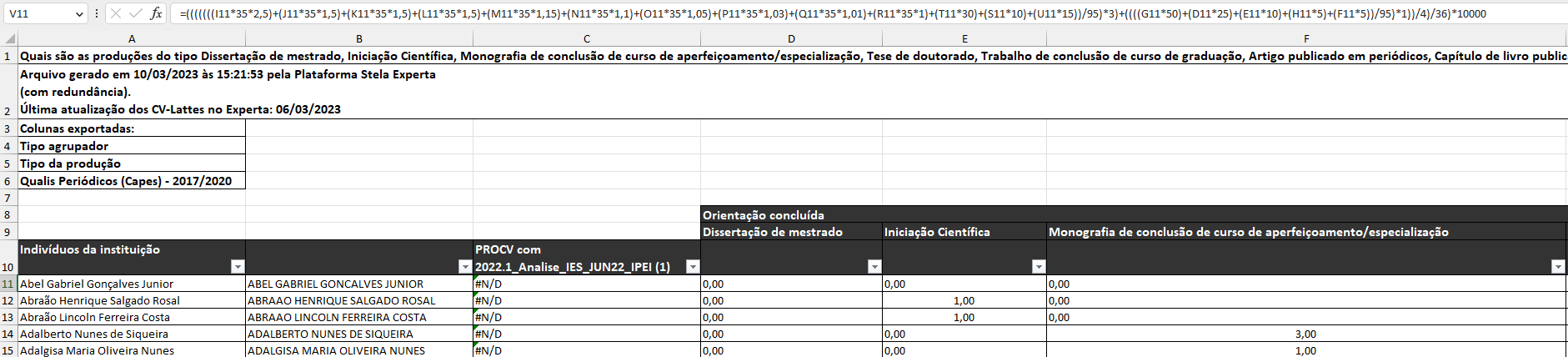
O primeiro projeto do LTD, realizado no período anterior, foi concluído com sucesso resultando na criação de scripts na linguagem Phyton para importação e geração de novas planilhas com o cálculo dos índices de produtividade.
Neste período a Dra. Larissa Clare Pochmann da Silva, procurou a equipe do LTD para melhorar o processo de importação de dados. Foi pedido que os dados dos professores sejam importados diretamente do servidor do CNPQ e sejam disponibilizados no formato CSV na mesma estrutura do arquivo de leitura do projeto anterior.
Justificativa
Diante do problema apresentado o campus Nova América organizou uma equipe LTD com ênfase em software para que os alunos dos cursos de Computação, Sistemas de Informação e Análise e Desenvolvimento de Sistemas pudessem trabalhar para automatizar o processo de extração de dados da Plataforma Lattes do CNPq. O grupo de alunos foi dividido em equipes como documentaçao e desenvolvimento de códigos simulando o trabalho em uma empresa do setor de software.
Objetivos/resultados/efeitos a serem alcançados (em relação ao problema identificado e sob a perspectiva dos públicos envolvidos)
- Efetuar a extração, transformação e carga dos dados;
Referencial teórico (subsídio teórico para propositura de ações da extensão)
O processo de Extração, Transformação e Carga (ETL) de dados (Navathe, 2005) dos docentes em uma universidade desempenha um papel crucial na análise e aprimoramento da produtividade acadêmica. O referencial teórico para este projeto de extensão busca contextualizar a importância dessa abordagem, destacando as bases conceituais e metodológicas que sustentam a eficiência do processo.
A produtividade acadêmica é uma dimensão vital para a avaliação e o aprimoramento contínuo das instituições de ensino superior. A coleta e análise de dados (Han, 2019), (Lopes, 2022) dos docentes são fundamentais para compreender o desempenho acadêmico, identificar padrões e oportunidades de melhoria. O processo de Extração, Transformação e Carga dos dados (ETL), como abordagem metodológica, permite a integração de dados de diferentes fontes, proporcionando uma visão abrangente e coesa do ambiente acadêmico.
A Extração refere-se à coleta de dados brutos de diversas fontes, como sistemas de gerenciamento acadêmico, plataformas de pesquisa e repositórios institucionais. A Transformação envolve a limpeza, padronização e enriquecimento desses dados, garantindo a consistência e a qualidade necessárias para análises precisas. A Carga consiste na inserção dos dados processados em um repositório central, preparando-os para análises e visualizações. No contexto da produtividade acadêmica, os índices são indicadores-chave que fornecem insights sobre a quantidade e a qualidade das atividades acadêmicas. Índices como número de publicações, participação em eventos científicos e orientações de alunos são cruciais para avaliar o impacto e a contribuição de cada docente. A aplicação do ETL a esses dados permite uma avaliação holística e dinâmica da produtividade.
No ambiente acadêmico em constante evolução, a adoção de tecnologias para aprimorar a gestão e análise de dados é imperativa. O referencial teórico deste projeto baseia-se na premissa de que o ETL, aliado à construção de um dashboard, oferece uma abordagem robusta e eficiente para a compreensão e aprimoramento da produtividade acadêmica. Ao integrar teoria e prática, este projeto visa contribuir significativamente para a excelência acadêmica e a tomada de decisões informadas na universidade.
PLANEJAMENTO E DESENVOLVIMENTO DO PROJETO
Casos de Uso
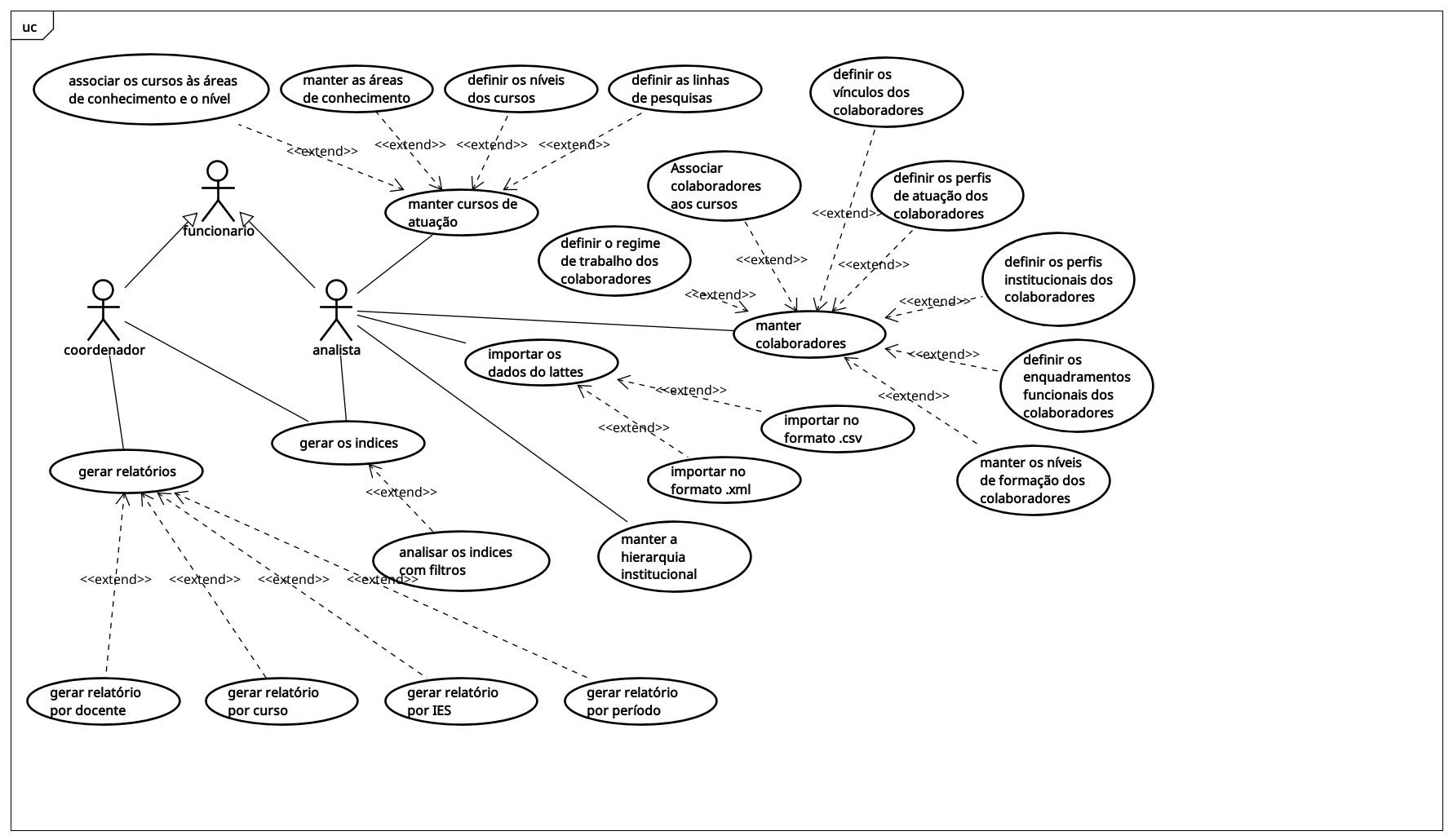
Descrição do caso de uso
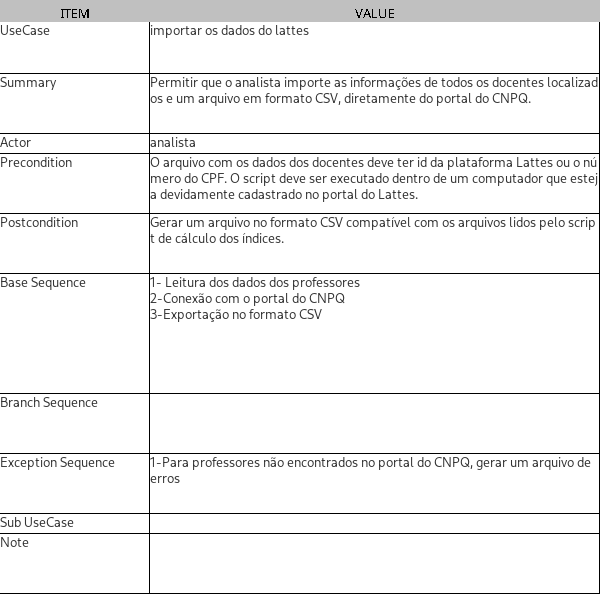
Didagrama de atividades
Código fonte do programa em Python
#!pip install xmltodict
#!pip install python-dotenv
#!pip install pandas
#!pip install requests
#!pip install openpyxl
import json
import pandas as pd
import xmltodict
import requests
import os
from datetime import date, datetime
import time
time_in_mil = round(time.time()*1000)
base_file = "./base_professores_lattes.xlsx"
log_file = f"./log_{time_in_mil}.json"
offset_file = "./offset.txt"
base_professores_original = pd.read_excel(base_file)
base_professores = base_professores_original
base_professores['ID_LATTES'] = base_professores['URL_LATTES'].str.split('/').str[-1]
base_professores['ID_LATTES_FINAL'] = base_professores['ID_LATTES']
base_professores.set_index('ID_LATTES', inplace=True)
def get_offset():
f = open(offset_file, "r").readline()
return f
def set_offset(offset):
try:
with open(offset_file, 'w+') as f_offset:
f_offset.write(offset)
f_offset.close()
except:
print(f"Nao foi possivel escrever o offset para o ID {offset}")
def write_log(log_message):
with open(log_file, 'a+') as outfile:
json.dump(log_message, outfile)
outfile.write(',\n')
outfile.close()
def build_cv_payload(id_prof):
payload = f"""<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:wsdl="http://br.cnpq.cvlattes.extracaocv/wsdl">
<soapenv:Header/>
<soapenv:Body>
<wsdl:extrairItens>
<!--Optional:-->
<request>
<!--Optional:-->
<parametros>
<!--Optional:-->
<anoInicio>2000</anoInicio>
<!--Optional:-->
<anoTermino>2023</anoTermino>
<!--Optional:-->
<idCNPq>{id_prof}</idCNPq>
<!--Zero or more repetitions:-->
<listaIdModuloItem>FORMACAO-ACADEMICA-TITULACAO</listaIdModuloItem>
</parametros>
</request>
</wsdl:extrairItens>
</soapenv:Body>
</soapenv:Envelope>"""
return payload
def build_date_payload(id_prof):
payload = f"""
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:ws="http://ws.servico.repositorio.cnpq.br/">
<soapenv:Header/>
<soapenv:Body>
<ws:getDataAtualizacaoCV>
<id>{id_prof}</id>
</ws:getDataAtualizacaoCV>
</soapenv:Body>
</soapenv:Envelope>
"""
return payload
def make_CVapi_call(payload, cv_id):
headers = {
'Content-Type': 'text/xml; charset=utf-8'
}
url= "http://servicosweb.cnpq.br/wsmodulocv/WSExtracaoCVLattesService/WSExtracaoCVLattesImpl?wsdl"
try:
response = requests.request("POST", url, headers=headers, data=payload)
return response
except:
return False
def make_DATEapi_call(payload, cv_id):
url= "http://servicosweb.cnpq.br/srvcurriculo/WSCurriculo?wsdl"
try:
response = requests.request("POST", url, data=payload)
return response
except:
return False
def clear_DATEapi_response(api_response, cv_id):
try:
obj = xmltodict.parse(api_response.text)
dt = obj["env:Envelope"]["env:Body"]['ws:getDataAtualizacaoCVResponse']["return"].split(" ")[0]
datetime_object = datetime.strptime(dt, '%d/%m/%Y').date()
return datetime_object
except:
return False
def clear_CVapi_response(api_response, cv_id):
try:
clean_lines = api_response.text.split("<xml>")[1].split("</xml>")[0].replace("""<?xml version="1.0" encoding="ISO-8859-1"?>""", "").replace("<", "<")
obj = xmltodict.parse(clean_lines)
status = get_grad_level(obj, cv_id)
except:
return False, False
return status, clean_lines
def get_grad_level(json_obj, cv_id):
grad_levels = ["GRADUACAO", "ESPECIALIZACAO", "MESTRADO", "DOUTORADO", "POS-DOUTORADO"]
status_acad = {"id": cv_id, "dt_atualizacao": str(date.today())}
for grad in grad_levels:
try:
temp = json_obj["CURRICULO-VITAE"]["DADOS-GERAIS"]["FORMACAO-ACADEMICA-TITULACAO"][grad]["@STATUS-DO-CURSO"]
if temp == "CONCLUIDO":
status_acad[grad] = 1
else:
status_acad[grad] = 0
except:
try:
temp = json_obj["CURRICULO-VITAE"]["DADOS-GERAIS"]["FORMACAO-ACADEMICA-TITULACAO"][grad][0]["@STATUS-DO-CURSO"]
if temp == "CONCLUIDO":
status_acad[grad] = 1
else:
status_acad[grad] = 0
except:
status_acad[grad] = 0
return status_acad
def start_processing(df, cv_id, has_grad):
print(f'Processando ID: {cv_id}')
payload = build_cv_payload(cv_id)
response = make_CVapi_call(payload, cv_id)
status_acad, plain_xml = clear_CVapi_response(response, cv_id)
if status_acad == False and has_grad == -1:
status = {'id': cv_id, 'dt_atualizacao': str(date.today()), 'GRADUACAO': -1, 'ESPECIALIZACAO': -1, 'MESTRADO': -1, 'DOUTORADO': -1, 'POS-DOUTORADO': -1}
elif status_acad == False and has_grad != -1:
return False # Não executar update do DF pra esse cenário
else:
status = status_acad
df.loc[[status["id"]], ["GRADUACAO", "ESPECIALIZACAO", "MESTRADO", "DOUTORADO", "POS-DOUTORADO", "dt_atualizacao", "unparsed_xml"]] = [status['GRADUACAO'], status['ESPECIALIZACAO'], status['MESTRADO'], status['DOUTORADO'], status['POS-DOUTORADO'], status["dt_atualizacao"], plain_xml]
return df
offset = get_offset()
base_execucao = base_professores.loc[offset:, ['ID_LATTES_FINAL', 'dt_atualizacao', 'GRADUACAO']]
len(base_execucao)
for index, row in base_execucao.iterrows():
ID = row['ID_LATTES_FINAL']
base_date = row['dt_atualizacao']
has_grad = row['GRADUACAO']
set_offset(ID)
if has_grad == 0 or has_grad == 1:
payload = build_date_payload(ID)
response = make_DATEapi_call(payload, ID)
dt_atualizacao_lattes = clear_DATEapi_response(response, ID) #objeto data
if dt_atualizacao_lattes is False:
continue
base_date = datetime.strptime(base_date, '%Y-%m-%d').date() #Transforma base_date para objeto data
if base_date < dt_atualizacao_lattes:
start_processing(base_professores, ID, has_grad)
else:
continue
else:
has_grad = -1
start_processing(base_professores, ID, has_grad)
final = base_professores.to_excel(f"base_professores_lattes_{time_in_mil}.xlsx")
2. Modelagem de dados para tabela de composição nutricional dos alimentos
Integrantes
| Nome | Função |
|---|---|
| André Eppinghaus | Coordenador |
| Felippe Kamisaki Camilato | Desenvolvedor |
| Sergio de Oliveira Marques | Desenvolvedor |
| Adailton Lima Freire | Desenvolvedor |
| Kaio Ramos da Silva | Desenvolvedor |
| Jean Souza Marques de Oliveira | Desenvolvedor |
| Bruna de Araujo Hara | Desenvolvedora |
| Evilásio Gonçalo das Neves Neto | Desenvolvedor |
DIAGNÓSTICO E TEORIZAÇÃO
Identificação das partes interessadas e parceiros
Empresa CodeWorker LTDA, localizada no Rio de janeiro, com a parte interessada o CEO da empresa o sr. Vicente Calfo e o CTO da empresa o sr. André Eppinghaus.
Problemática e/ou problemas identificados
A empresa CodeWorker LTDA, possui uma equipe reduzida e necessita criar uma estrutura de dados, a partir dos dados extraídos da Tabela Brasileira de Composicao de Alimentos - TACO 4, e de outras tabelas relacionadas, com o intuito de construir uma base limpa e precisa para uso interno de seus aplicativos.
Justificativa
Diante do problema apresentado o campus Nova América organizou uma equipe LTD com ênfase em software para que os alunos dos cursos de Computação, Sistemas de Informação e Análise e Desenvolvimento de Sistemas pudessem trabalhar para modelar, extrair, tratar e construir um modelo de bando de dados relacional para atender o objetivo. O grupo de alunos foi dividido em equipes como documentação e desenvolvimento de códigos simulando o trabalho em uma empresa do setor de software.
Objetivos/resultados/efeitos a serem alcançados (em relação ao problema identificado e sob a perspectiva dos públicos envolvidos)
- Efetuar a extração, transformação e carga dos dados;
Referencial teórico (subsídio teórico para propositura de ações da extensão)
O processo de Extração, Transformação e Carga (ETL) de dados (Navathe, 2005) dos docentes em uma universidade desempenha um papel crucial na análise e aprimoramento da produtividade acadêmica. O referencial teórico para este projeto de extensão busca contextualizar a importância dessa abordagem, destacando as bases conceituais e metodológicas que sustentam a eficiência do processo.
A produtividade acadêmica é uma dimensão vital para a avaliação e o aprimoramento contínuo das instituições de ensino superior. A coleta e análise de dados (Han, 2019), (Lopes, 2022) dos docentes são fundamentais para compreender o desempenho acadêmico, identificar padrões e oportunidades de melhoria. O processo de Extração, Transformação e Carga dos dados (ETL), como abordagem metodológica, permite a integração de dados de diferentes fontes, proporcionando uma visão abrangente e coesa do ambiente acadêmico.
A Extração refere-se à coleta de dados brutos de diversas fontes, como sistemas de gerenciamento acadêmico, plataformas de pesquisa e repositórios institucionais. A Transformação envolve a limpeza, padronização e enriquecimento desses dados, garantindo a consistência e a qualidade necessárias para análises precisas. A Carga consiste na inserção dos dados processados em um repositório central, preparando-os para análises e visualizações. No contexto da produtividade acadêmica, os índices são indicadores-chave que fornecem insights sobre a quantidade e a qualidade das atividades acadêmicas. Índices como número de publicações, participação em eventos científicos e orientações de alunos são cruciais para avaliar o impacto e a contribuição de cada docente. A aplicação do ETL a esses dados permite uma avaliação holística e dinâmica da produtividade.
No ambiente acadêmico em constante evolução, a adoção de tecnologias para aprimorar a gestão e análise de dados é imperativa. O referencial teórico deste projeto baseia-se na premissa de que o ETL, aliado à construção de um dashboard, oferece uma abordagem robusta e eficiente para a compreensão e aprimoramento da produtividade acadêmica. Ao integrar teoria e prática, este projeto visa contribuir significativamente para a excelência acadêmica e a tomada de decisões informadas na universidade.
PLANEJAMENTO E DESENVOLVIMENTO DO PROJETO
Casos de Uso
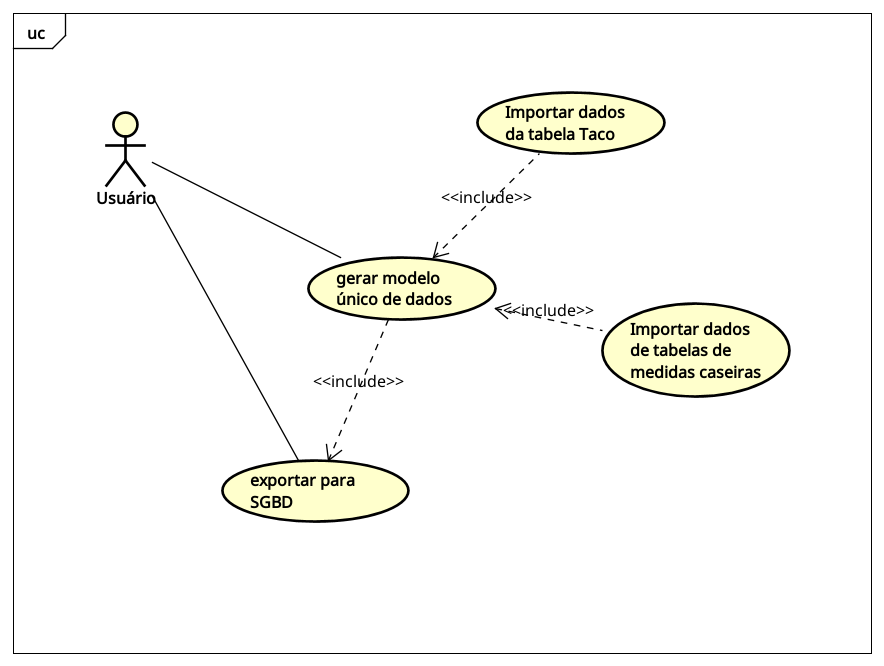
Descrição do caso de uso
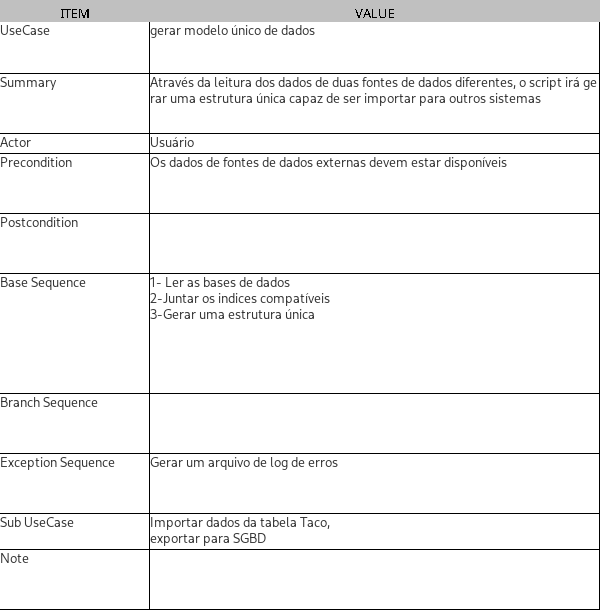
Diagrama de atividades

3. Criação de uma biblioteca (Pyhton e C) para Arduino utilizando equipamentos do LTD
Integrantes
| Nome | Função |
|---|---|
| André Eppinghaus | Coordenador |
| Yuri Guerra Rodrigues | Desenvolvedor |
| Rodrigo Dias Martins | Desenvolvedor |
| Lucas dos Santos Missiba | Desenvolvedor |
| Michel Hermínio do Nascimento | Desenvolvedor |
| Leonardo Santos de Carvalho | Desenvolvedor |
| Yan Sacramento De Gouveia | Desenvolvedor |
| Aline Silva | Desenvolvedora |
| Guilherme Pacheco Vivone Martins | Desenvolvedor |
DIAGNÓSTICO E TEORIZAÇÃO
Identificação das partes interessadas e parceiros
O coordenador Rodrigo Augusto dos cursos de Computação, Sistemas de Informação e Análise e Desenvolvimento de Sistemas da Univesidade Estácio de Sá (UNESA), campus Nova América, recebeu uma doação de uma Plataforma de prototipagem de hardware com ESP32.
Problemática e/ou problemas identificados
Com o intuito de facilitar o acesso dos alunos ao protótipo, o coordenador Rodrigo solicitou ao LTD a criação de uma Interface de programação de aplicações (API) nas linguagens Python e C++.
Justificativa
Diante do problema apresentado o campus Nova América organizou uma equipe LTD com ênfase em software para que os alunos dos cursos de Computação, Sistemas de Informação e Análise e Desenvolvimento de Sistemas pudessem trabalhar para modelar, extrair, tratar e construir uma API para atender o objetivo. O grupo de alunos foi dividido em equipes como documentação e desenvolvimento de códigos simulando o trabalho em uma empresa do setor de software.
Objetivos/resultados/efeitos a serem alcançados (em relação ao problema identificado e sob a perspectiva dos públicos envolvidos)
- Pesquisar os sensores;
- Criar códigos isolados nas linguagens Python e em C++;
- Criar uma classe para cada linguagem;
- Disponiliblizar no github.
Referencial teórico (subsídio teórico para propositura de ações da extensão)
O processo de Extração, Transformação e Carga (ETL) de dados (Navathe, 2005) dos docentes em uma universidade desempenha um papel crucial na análise e aprimoramento da produtividade acadêmica. O referencial teórico para este projeto de extensão busca contextualizar a importância dessa abordagem, destacando as bases conceituais e metodológicas que sustentam a eficiência do processo.
A produtividade acadêmica é uma dimensão vital para a avaliação e o aprimoramento contínuo das instituições de ensino superior. A coleta e análise de dados (Han, 2019), (Lopes, 2022) dos docentes são fundamentais para compreender o desempenho acadêmico, identificar padrões e oportunidades de melhoria. O processo de Extração, Transformação e Carga dos dados (ETL), como abordagem metodológica, permite a integração de dados de diferentes fontes, proporcionando uma visão abrangente e coesa do ambiente acadêmico.
A Extração refere-se à coleta de dados brutos de diversas fontes, como sistemas de gerenciamento acadêmico, plataformas de pesquisa e repositórios institucionais. A Transformação envolve a limpeza, padronização e enriquecimento desses dados, garantindo a consistência e a qualidade necessárias para análises precisas. A Carga consiste na inserção dos dados processados em um repositório central, preparando-os para análises e visualizações. No contexto da produtividade acadêmica, os índices são indicadores-chave que fornecem insights sobre a quantidade e a qualidade das atividades acadêmicas. Índices como número de publicações, participação em eventos científicos e orientações de alunos são cruciais para avaliar o impacto e a contribuição de cada docente. A aplicação do ETL a esses dados permite uma avaliação holística e dinâmica da produtividade.
No ambiente acadêmico em constante evolução, a adoção de tecnologias para aprimorar a gestão e análise de dados é imperativa. O referencial teórico deste projeto baseia-se na premissa de que o ETL, aliado à construção de um dashboard, oferece uma abordagem robusta e eficiente para a compreensão e aprimoramento da produtividade acadêmica. Ao integrar teoria e prática, este projeto visa contribuir significativamente para a excelência acadêmica e a tomada de decisões informadas na universidade.
PLANEJAMENTO E DESENVOLVIMENTO DO PROJETO
Casos de Uso
em construção
Descrição do caso de uso
em construção
Didagrama de atividades
em construção
![]()